Back to Labs Content
- Distributed Systems
- Deployment
Multi-Service Deployment Strategies: Rolling Updates, Blue-Green, and Canary
Wednesday, May 21, 2025 at 4:03:04 PM GMT+8
Deploying updates in a microservices architecture demands strategies that balance uptime, stability, and resource efficiency. Three popular approaches—Rolling Updates, Blue-Green Deployment, and Canary Deployment—offer distinct ways to manage multi-service deployments. Let’s dive into how they work, their pros and cons, and how they fit into a multi-service environment.
Rolling Updates: Gradual Replacement for Minimal Disruption
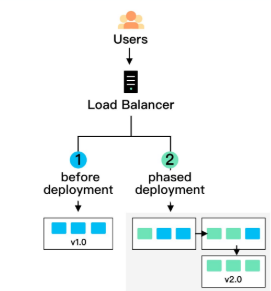
Rolling Updates involve updating services incrementally, replacing old versions with new ones one at a time while keeping the system operational.
How It Works: Each service is updated sequentially. For example, if you have multiple instances of Service A running version 1.0, you update one instance to version 1.1, verify its stability, then proceed to the next instance until all are updated.
Pros:
- Minimal Downtime: The system remains available as updates are applied gradually.
- Easy Rollback: If an issue arises, you can roll back individual services without affecting the entire system.
- Ideal for Loosely Coupled Services: Works well when services don’t need to be updated simultaneously.
Cons:
- Slower Process: Updating many services takes time, especially with large systems.
- Version Mismatch Risk: Temporary discrepancies between service versions can cause compatibility issues.
Rolling Updates are a solid choice for teams prioritizing simplicity and minimal resource overhead, though they require careful monitoring to avoid version conflicts.
Blue-Green Deployment: Seamless Switches for Zero Downtime

Blue-Green Deployment uses two environments to update services without stopping them: one for the current version (Blue) and one for the new version (Green). The diagram shows this in action. On the left, the Staging environment acts as Blue, running Service A and Service B at version 1.1, while the Production environment serves as Green, preparing Service C and Service D at version 1.0. After testing the new versions, the upgrade switches traffic so that, on the right, Production becomes Blue with the old versions (Service A and B at v1.1) as a backup, and Staging takes over as Green with the new versions (Service C and D at v1.0).
Pros:
- Near-Zero Downtime: Traffic switches instantly, keeping users unaffected.
- Instant Rollback: Revert to Blue if issues arise.
- Full System Validation: Test the entire system in Green before going live.
Cons:
- Resource Intensive: Requires maintaining two environments, doubling costs.
- Complex Management: Coordinating dual environments can be challenging.
This strategy is perfect for systems where downtime is unacceptable, especially for tightly coupled services that need simultaneous updates.
Canary Deployment: Gradual Rollouts with Real-User Insights
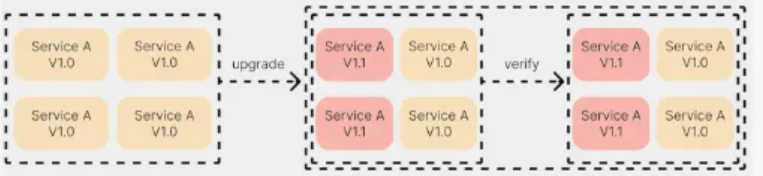
Canary Deployment rolls out updates to a small subset of users first, minimizing risk. The diagram shows Service A with version 1.0 across multiple instances, while version 1.1 is deployed to a few instances, with traffic gradually shifted after verification.
How It Works: Deploy the new version (e.g., Service A v1.1) to a small group of instances, route a portion of traffic to it, monitor performance, and increase traffic to 100% if successful. Roll back to v1.0 if issues are detected.
Pros:
- Limited Blast Radius: Issues affect only a small user group.
- Real-User Feedback: Early insights from live usage help catch problems.
- Automation-Friendly: Works well with monitoring and traffic routing tools.
Cons:
- Complex Setup: Requires advanced routing and monitoring systems.
- Longer Deployment Time: Gradual rollouts take longer.
Canary Deployment is ideal for large-scale systems where testing with real users is crucial before a full rollout.
Choosing the Right Strategy for Your Team
Choosing the Right Strategy for Your Team
When deciding on a deployment strategy for your multi-service environment, understanding the unique strengths and trade-offs of each approach is key to aligning with your team’s goals and infrastructure capabilities. Rolling Updates, Blue-Green Deployment, and Canary Deployment each cater to different needs, and selecting the right one depends on your priorities around downtime, resource availability, and risk tolerance.
Rolling Updates offer a straightforward and resource-efficient way to deploy updates across your services. By updating one instance at a time, this method ensures the system remains operational throughout the process, making it an excellent choice for teams working with limited infrastructure or loosely coupled services. However, its gradual nature means the deployment can take longer, especially in systems with many services. Additionally, there’s a risk of temporary version mismatches between services, which could lead to compatibility issues if not carefully managed. This approach is best for teams who value simplicity and are prepared to monitor for potential conflicts during the rollout.
In contrast, Blue-Green Deployment prioritizes seamless transitions and minimal downtime, making it ideal for systems where user experience cannot be compromised. By maintaining two identical production environments—Blue for the current version and Green for the new version—this strategy allows you to deploy and test all updated services in Green before instantly switching all traffic from Blue to Green. The Blue environment acts as a safety net, enabling immediate rollback if issues arise. While this ensures near-zero downtime and allows for thorough validation of the entire system, it comes at the cost of higher resource demands, as you need to sustain two fully operational environments. Managing these dual environments also adds complexity, so this method suits teams with the resources and expertise to handle such setups, particularly when dealing with tightly coupled services that require simultaneous updates.
Canary Deployment, on the other hand, takes a cautious approach by rolling out updates to a small subset of users or traffic before a full deployment. This gradual rollout lets you monitor the new version’s performance with real users, providing valuable feedback and limiting the impact of potential issues to a smaller audience. If the new version performs well, you can incrementally increase traffic until it handles the full load; if problems emerge, you can quickly revert to the older version. This method excels in large-scale systems where real-world validation is critical, and it integrates well with automated monitoring and traffic routing tools. However, the setup can be complex, requiring sophisticated systems to manage traffic and track performance metrics. The deployment process also takes longer due to its phased nature, making it less suitable for teams needing rapid updates. Canary Deployment is a strong fit for teams who prioritize safety and have the infrastructure to support detailed monitoring.
Ultimately, your choice depends on your system’s complexity, the level of risk you’re willing to accept, and the resources at your disposal. Whether you opt for the simplicity of Rolling Updates, the zero-downtime assurance of Blue-Green Deployment, or the careful validation of Canary Deployment, each strategy offers a tailored way to manage the challenges of multi-service deployments effectively.
Wrapup
As we’ve explored, managing updates in a microservices world comes down to choosing the right strategy. Rolling Updates keep things simple and running with minimal resources, though they might face version hiccups—best for straightforward setups. Blue-Green Deployment ensures zero downtime by switching between two environments, perfect for services that can’t stop, even if it costs more. Canary Deployment tests changes with a few users first, offering safety and real feedback, ideal for larger systems with good monitoring. Depending on your team’s needs—whether it’s ease, uptime, or careful rollout—pick the one that fits.
Another Recommended Labs Content
How to Stop Microservices Failures from Spreading with the Bulkhead Pattern
Microservices are awesome for building apps that scale and evolve quickly. But as your system grows, a small problem in one service can snowball into a disaster, taking down your entire application. This is called a cascading failure, and it’s a big challenge in microservices. The Bulkhead Pattern is a smart way to prevent this by isolating parts of your system so one failure doesn’t sink everything else.
From Kubernetes Overload to Observability: How the Sidecar Pattern in Service Mesh Saves the Day
Kubernetes, a popular tool, helps manage these pieces by running them in containers and ensuring they’re available and scalable. But as your application grows, Kubernetes alone can’t handle everything. Let’s break this down and see how the sidecar pattern in a service mesh comes to the rescue, making your system easier to monitor, secure, and manage.
In modern software architecture, microservices have become the go-to approach for building scalable, maintainable, and independently deployable applications. However, with great modularity comes great complexity—especially when it comes to managing data consistency across services.