Back to Labs Content
- Data
- System Design
- Software Architecture
- Storage
Understanding Hadoop Distributed File System (HDFS)
Sunday, September 29, 2024 at 5:29:46 AM GMT+8
How HDFS Stands Out from Traditional File Systems
Have you ever wondered how Hadoop handles those massive datasets? It’s not quite like how your typical computer saves files using NTFS or FAT32. Let's break it down!
What is HDFS?
HDFS, or Hadoop Distributed File System, is the backbone of Hadoop. It’s specially built to handle huge volumes of data by spreading it across multiple machines, making it perfect for big data tasks. If you’ve got terabytes or even petabytes of information, HDFS can manage it efficiently.
Unlike regular file systems like NTFS (which you might find on your Windows laptop), HDFS isn't just about saving files locally. Instead, it breaks your files into chunks (called blocks), and then spreads them out over several machines. This allows Hadoop to process multiple pieces of data at the same time. Pretty neat, right?
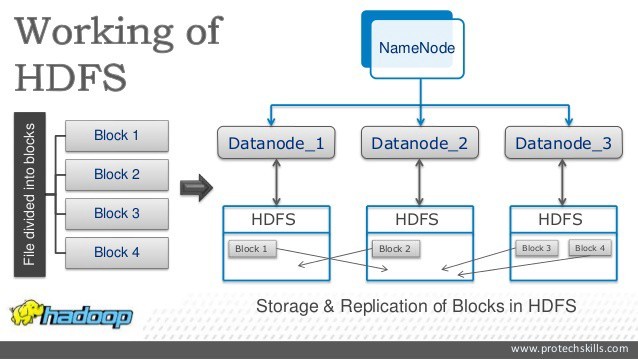
The Magic of HDFS: Why Blocks and Replication Matter
Here’s where HDFS gets really clever: it doesn’t just save your data in one place. It cuts files into large blocks, then duplicates (or replicates) those blocks across several machines. Why? So that if one machine crashes, your data isn’t lost. It’s all about fault tolerance.
Think of it like this: Imagine you’ve got a giant puzzle, but instead of keeping all the pieces in one box, you spread them across three different boxes. That way, even if you lose one box, you’ve still got enough pieces in the other two to complete the picture. That’s how replication in HDFS works. Each block is typically copied three times (though you can change that number if you need more or fewer backups).
Comparing HDFS to NTFS
Now, let’s compare this to NTFS. NTFS is a file system that works great for smaller files and doesn’t need to worry about distributing data over a network. When you save a file on your laptop, NTFS does its job locally—no fancy distribution happening here. If your hard drive fails, well, you better hope you’ve got a backup.
On the other hand, HDFS shines in situations where you're dealing with Big Data. Imagine trying to process a massive log file for an entire year across multiple servers. That’s when HDFS steps in to spread the workload across dozens or even hundreds of machines, making everything faster and more reliable.
How Clusters Work in HDFS
HDFS operates on a master-slave architecture, which, despite the name, is simpler than it sounds. Picture a group project where one person (the master) assigns tasks, and the rest (the slaves) carry them out. In Hadoop’s case, the NameNode is the master that keeps track of which machines (or DataNodes) are storing which blocks of data.
But here's the cool part: even if one of the DataNodes goes offline, you won't lose your data. Thanks to replication, other copies of the data are safe on different nodes. The NameNode makes sure that if something goes wrong, the system automatically reassigns tasks to healthy machines. So, your project continues without missing a beat.
Blocks and Replication: The Heart of HDFS
When you upload a file to HDFS, it doesn’t store the file in one piece. Instead, it breaks it into blocks—big ones, usually around 128 MB or 256 MB each (way bigger than what you'd see in NTFS or FAT32). These blocks are then distributed across multiple machines, and each block is typically replicated three times, just in case something goes wrong.
Let’s say you’ve uploaded a 1 GB file. HDFS would split that file into eight blocks, each around 128 MB. Then, it spreads these blocks out, saving them on different machines. And, for good measure, it replicates each block three times, storing those copies on different nodes. So even if one machine dies, the system still has two copies of every block.
This is what makes HDFS so powerful—by distributing both the data and the risk of failure, it allows Hadoop to manage enormous datasets without constantly worrying about losing data due to hardware issues.
What Happens When You Write Data to HDFS?
Here’s how the process goes when you write data to HDFS:
- Request: You, or an application, send a request to HDFS to save some data.
- Communication: HDFS, through the NameNode, checks where your data should be stored. It’s like asking the master project manager where to put each piece of the puzzle.
- Breaking into Blocks: The data is then broken down into blocks and sent to different DataNodes, which store those blocks.
- Replication: As each block gets stored, it's also replicated across other nodes. If one copy goes missing, the system can recreate it from another.
- Confirmation: Once all blocks are safely stored and replicated, HDFS sends a confirmation, saying, “All good! Your data’s safely stored.”
This process happens behind the scenes, but it's crucial to keeping your data safe and your big data applications running smoothly.
What Happens When a DataNode Fails in HDFS?
Imagine you're managing a vast library, and each book is split into multiple copies stored across different branches to ensure none of the information is lost. Now, what if one of the branches burns down? You wouldn't panic, right? Why? Because the other branches still hold copies. This is pretty much how Hadoop handles DataNode failures.
DataNodes store chunks of data, and it's inevitable that sometimes, things will go wrong. Maybe a server breaks down, or there's a network issue. But here’s the cool part: Hadoop has it all covered.
How Does Hadoop Know a DataNode Failed?
Think of it like a regular check-in system. Every few seconds, each DataNode sends a simple signal to the NameNode (the master controller) saying, “Hey, I’m here, and I’m working!” These signals are called heartbeats.
But what if the NameNode doesn’t hear from a DataNode? If it misses several heartbeats in a row, the NameNode starts to get suspicious. After a certain time, it officially declares, “This DataNode is down!”
What Happens Next?
Now, this is where Hadoop shows off its resilience. The moment a DataNode fails, the NameNode updates its metadata. Basically, it marks all the data blocks that were on that failed node as unavailable.
But remember—Hadoop doesn’t store just one copy of your data. It replicates blocks across multiple DataNodes. So, even though one DataNode has failed, the same data is safely stored on other DataNodes. The NameNode immediately gets to work, ensuring that all data remains fully backed up. It checks if any data blocks have dropped below the desired number of replicas (usually 3), and if so, it orders other healthy DataNodes to make fresh copies.
Bringing a DataNode Back to Life
Let’s say the failed DataNode eventually comes back online. It’s not like Hadoop just forgets about it. First, the NameNode checks whether the data stored there is still relevant. If the system has already made new replicas of those blocks, it might decide to remove the old, now-duplicated data to free up space.
Once the DataNode starts sending its heartbeats again, it gets reintegrated into the system, and life goes on as if nothing happened. It’s like having a team member who took a break and is now ready to get back to work!
In a nutshell, when a DataNode fails, Hadoop's architecture ensures there's no reason to worry. The NameNode quickly detects the failure, handles it behind the scenes by replicating data to other nodes, and everything continues running smoothly without missing a beat! Pretty smart, right?
Wrapping Up
HDFS might seem complex at first, but once you break it down, it’s really all about efficiency and reliability. By splitting files into blocks, distributing them across multiple machines, and replicating them for safety, HDFS ensures that your data is always accessible—even when things go wrong. So, if you're working with big datasets, HDFS is the perfect solution to keep everything running like clockwork.
Another Recommended Labs Content
Understanding Database Partitioning vs Sharding: Concepts, Benefits, and Challenges
When dealing with large volumes of data, efficient database management becomes essential. Two widely used techniques to improve performance and scalability are database partitioning and database sharding. Although often confused, these approaches differ fundamentally in architecture, complexity, and suitable use cases. This article explores these differences in detail, helping you decide which fits your application best.
System Design Simplified: The Trade-Off Triangle You Must Master
Behind every well-architected system is a set of tough decisions. The CAP Theorem simplifies those decisions by showing you what you must give up to keep your system fast, correct, and resilient. Learn how to apply this in real-world architecture.
Why Domain-Driven Design (DDD) Matters: From Chaos to Clarity in Complex Systems
Domain-Driven Design (DDD) is a powerful approach to software development that places the business domain—not the technology—at the center of your design decisions. First introduced by Eric Evans, DDD is essential for developers and architects who want to build systems that reflect real-world complexity and change.