Back to Labs Content
- Data
- Software Architecture
- System Design
- Storage
Mastering Apache Spark: An Engaging Dive into Its Architecture and Clusters
Monday, October 7, 2024 at 5:37:09 AM GMT+8
Spark Architecture
Imagine a Spark application as a bustling city. At the heart of this city is the Driver Program, which acts like the mayor overseeing everything that happens. The driver program is responsible for running your code, coordinating work, and making key decisions about how tasks should be executed. Like a city planner, it organizes and manages the tasks to be performed by the cluster, breaking down large jobs into smaller units of work. These jobs are then divided into tasks that Spark can run in parallel. The beauty of this architecture lies in its ability to scale, allowing multiple tasks to be completed simultaneously on different data partitions. These tasks are dispatched to executors, which are the hard workers of the cluster, doing the heavy lifting.
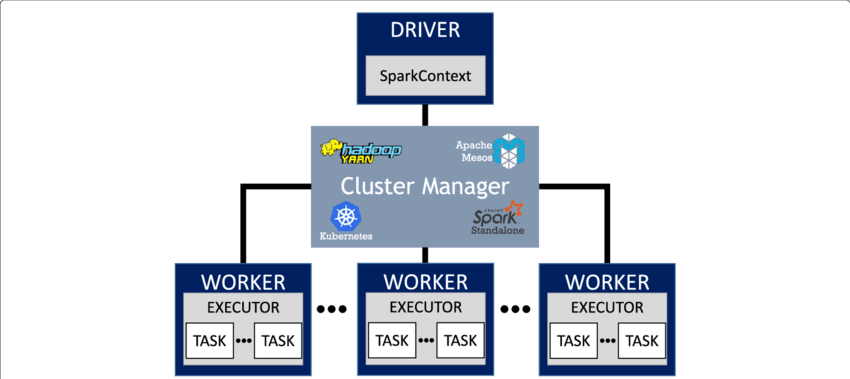
Executors are independent workers spread across the cluster, each taking responsibility for a portion of the work. They are not just performing tasks but are also responsible for caching data, which can speed up future computations by reusing cached data rather than starting from scratch. Much like how a construction team works efficiently by reusing tools and materials at the job site, executors are optimized to perform computations without redundant effort.
To help you better visualize this, think of a project that requires breaking down and shipping parts to different locations. Each part can be processed independently and reassembled once all pieces are completed. The driver program ensures these tasks are coordinated correctly, and executors handle each piece of the job.
But what’s the relationship between jobs, tasks, and stages? Imagine you're the head of a large construction project, and you need to break down the overall project (the job) into manageable tasks for each construction team. A task in Spark operates on a specific partition of data, much like a construction team focusing on a particular section of the building. Once a group of tasks that don’t depend on any other data is identified, Spark bundles them into stages. A stage represents a set of tasks that can be executed independently without needing data from elsewhere in the project. However, sometimes a task will need information from another part of the dataset, requiring what’s known as a data shuffle. This shuffle is like coordinating deliveries between different construction teams—an operation that can slow things down due to the necessary data exchange, but essential for the overall completion of the job.
What happens when Spark needs to run in different environments? That’s where cluster modes come in. There are several ways Spark can be deployed, each suited to different use cases. The simplest is local mode, ideal for testing on your own machine. Imagine local mode as running your city’s planning department with just one employee—the driver program manages everything on its own, without help from external workers. This is great for testing, but when you need real performance, it’s time to deploy Spark in a cluster.
In a full cluster setup, Spark supports several modes. Spark Standalone is the quickest way to set up a cluster environment, ideal for smaller projects or when you want complete control over the infrastructure. For those already working in large-scale environments with Hadoop, YARN is a natural choice. It integrates seamlessly with the broader Hadoop ecosystem, making it easy to manage resources. For greater flexibility and the ability to handle dynamic workloads, Apache Mesos comes into play, providing a more robust partitioning and scaling system.
But if you’re looking for a modern, cloud-native approach, Kubernetes offers powerful benefits. Running Spark on Kubernetes is like managing a city that can grow or shrink as needed, using containers to deploy and scale your Spark applications. With Kubernetes, Spark becomes highly portable, making it easy to run your Spark jobs in any cloud environment. You can set up your Spark application inside containers and have them scale automatically based on demand, ensuring smooth processing even as workloads increase.
Mastering the Art of Running Apache Spark Applications
Ever wondered how to launch your Apache Spark application into action? Whether you’re processing mountains of data or just running local tests, Apache Spark’s flexibility makes it incredibly powerful. But let’s be real—understanding how to run a Spark application might seem daunting at first. Fear not! Here’s your step-by-step guide to Spark mastery.
At the heart of it all is the spark-submit script. Think of it as Spark’s personal conductor, ensuring your application runs smoothly across a distributed cluster or right on your local machine. With spark-submit, you’ve got full control: it lets you specify everything from the cluster manager you want to connect to, to how much memory and CPU cores your application needs. You can also include any additional files or libraries your app requires, making sure all the pieces are in place for a flawless run.
Now, let’s talk dependencies. In Spark, making sure the driver and executors have access to the right libraries is crucial. If you’re using Java or Scala, bundling all your code and libraries into a single uber-JAR (or fat JAR) is a common approach. This neat package ensures that everything is shipped out and accessible where it’s needed. For Python applications—aka PySpark—you’ll want to ensure that each node in your cluster has the exact same Python libraries installed. Imagine trying to run a marathon with mismatched shoes—it won’t end well, right? Same idea with your Spark dependencies.
If you’re in the mood for a more hands-on, experimental approach, then the Spark Shell is your playground. This interactive tool lets you dive right into Spark with either Scala or Python, without needing to write and submit an entire application. When you fire up the Spark Shell, it automatically sets up everything for you—giving you instant access to Spark’s APIs. You can run quick computations, play around with datasets, and see the results in real-time, making it perfect for debugging or just satisfying your curiosity.
So, to sum it all up: running an Apache Spark application is as easy as using spark-submit to launch your code, bundling your dependencies into an uber-JAR (or ensuring Python libraries are ready), and—if you're feeling adventurous—jumping into the Spark Shell for some interactive magic. Spark truly puts the power of distributed computing at your fingertips.
We now trying to submit Apache Spark applications from a python script. This exercise is straightforward thanks to Docker Compose. In this lab, you will:
- Install a Spark Master and Worker using Docker Compose
- Create a python script containing a spark job
- Submit the job to the cluster directly from python (Note: you’ll learn how to submit a job from the command line in the Kubernetes Lab)
Install a Apache Spark cluster using Docker Compose
git clone https://github.com/big-data-europe/docker-sparkchange to that directory and attempt to docker-compose up
cd docker-spark
docker-compose upAfter quite some time you should see the following message:
Successfully registered with master spark://<server address>:7077
Create Code
import findspark
findspark.init()
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import StructField, StructType, IntegerType, StringType
sc = SparkContext.getOrCreate(SparkConf().setMaster('spark://localhost:7077'))
sc.setLogLevel("INFO")
spark = SparkSession.builder.getOrCreate()
spark = SparkSession.builder.getOrCreate()
df = spark.createDataFrame(
[
(1, "foo"),
(2, "bar"),
],
StructType(
[
StructField("id", IntegerType(), False),
StructField("txt", StringType(), False),
]
),
)
print(df.dtypes)
df.show()Execute code / submit Spark job
Now we execute the python file we saved earlier.
In the terminal, run the following commands to upgrade the pip installer to ensure you have the latest version by running the following commands.Now we execute the python file we saved earlier.
rm -r ~/.cache/pip/selfcheck/
pip3 install --upgrade pip
pip install --upgrade distro-infoPlease enter the following commands in the terminal to download the spark environment.
wget https://archive.apache.org/dist/spark/spark-3.3.3/spark-3.3.3-bin-hadoop3.tgz
&& tar xf spark-3.3.3-bin-hadoop3.tgz && rm -rf spark-3.3.3-bin-hadoop3.tgzRun the following commands to set up the which is preinstalled in the environment and which you just downloaded.
export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
export SPARK_HOME=/home/project/spark-3.3.3-bin-hadoop3Install the required packages to set up the spark environment.
pip install pyspark
python3 -m pip install findsparkType in the following command in the terminal to execute the Python script.
python3 submit.pygo to port 8080 to see the admin UI of the Spark master
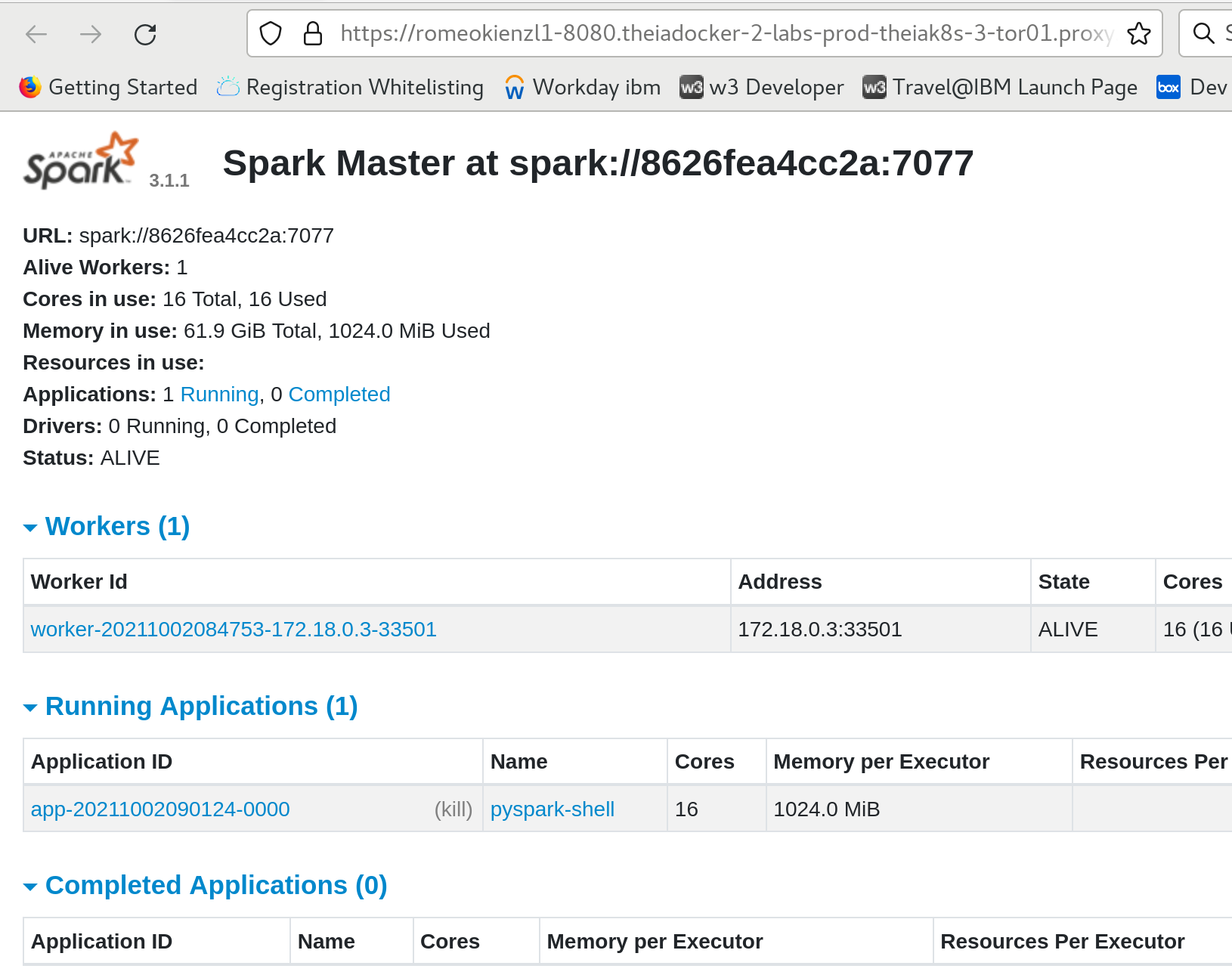
Look at that! You can now see all your registered workers (we’ve got one for now) and the jobs you’ve submitted (just one at the moment) through Spark's slick interface. Want to dig even deeper? You can access the worker’s UI by heading to port 8081 and see what’s happening under the hood!
In this hands-on lab, you've set up your very own experimental Apache Spark cluster using Docker Compose. How cool is that? Now, you can easily submit Spark jobs directly from your Python code like a pro!
But wait, there’s more! In our next adventure—the Kubernetes lab—you’ll unlock the power of submitting Spark jobs right from the command line.
Another Recommended Labs Content
Understanding Database Partitioning vs Sharding: Concepts, Benefits, and Challenges
When dealing with large volumes of data, efficient database management becomes essential. Two widely used techniques to improve performance and scalability are database partitioning and database sharding. Although often confused, these approaches differ fundamentally in architecture, complexity, and suitable use cases. This article explores these differences in detail, helping you decide which fits your application best.
System Design Simplified: The Trade-Off Triangle You Must Master
Behind every well-architected system is a set of tough decisions. The CAP Theorem simplifies those decisions by showing you what you must give up to keep your system fast, correct, and resilient. Learn how to apply this in real-world architecture.
Why Domain-Driven Design (DDD) Matters: From Chaos to Clarity in Complex Systems
Domain-Driven Design (DDD) is a powerful approach to software development that places the business domain—not the technology—at the center of your design decisions. First introduced by Eric Evans, DDD is essential for developers and architects who want to build systems that reflect real-world complexity and change.